GAMES202 Lecture 04 - Real-Time Shadows 2
GAMES202_Lecture_04 (ucsb.edu)
I. More on PCF and PCSS
The Principle behind PCF/PCSS
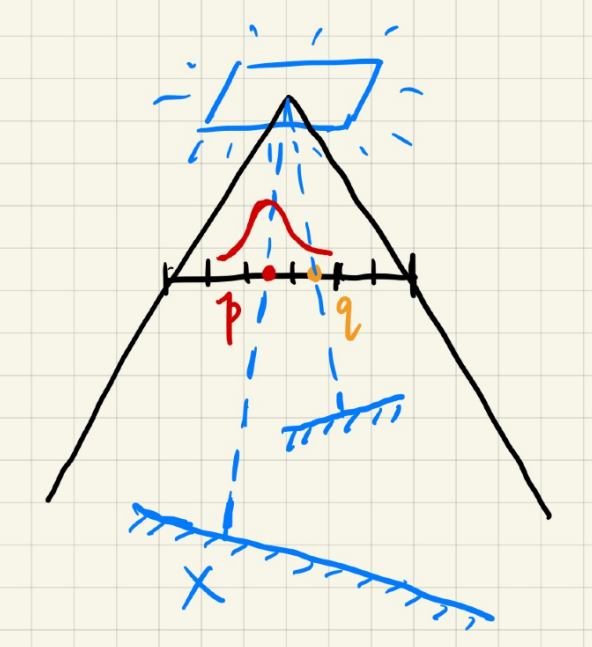
Consider the Neighboring Region: For any point
Weighted Consideration: When we average the entire region with all weights set to
Filter/Convolution: Averaging w.r.t. to a specific distribution is essentially filter/convolution.
where:
In PCSS:
For any shading point
For any texel
Thus, we have the following conclusions:
PCF is not filtering the shadow map and then comparing:
Which still leads to binary visibilities
PCF is not filtering the resulting image with binary visibilities:
In other words, PCF is not filtering the resultant shadow.
Performance Issue in PCSS
Given the PCSS algorithm:
Blocker Search:
Get the average blocker depth in a certain region inside the shadow map
Penumbra Estimation:
Use the average blocker depth to determine filter size
Percentage Closer Filtering
Which steps can be slow in PCSS?
Examining every texel in a certain region (steps 1 and 3)
Sample:
May use sparse sampling, and then apply image-space denoising.
Introducing noise.
MIPMAP
Softer -> Larger Filtering Region -> Slower
II. Variance (Soft) Shadow Mapping (VSM/VSMM)
What is new in VSM/VSMM:
Fast blocker search (step 1) and filtering (step 3) [Yang et al.]
Speeding up PCF
Predict the percentage of texels that are in front of the shading point:
Using a normal distribution to approximate the answer
Or, we may directly apply Chebyshev's inequality without assuming the distribution
Key Idea
Using probability theories to approximate the answer.
Quickly compute the mean and variance of depths in an area
Mean (Average):
Hardware MIPMAP (Range-Average Query)
Summed Area Tables (SAT)
How to? See Section III.
Variance:
Quick Computation: Use depth squared.
Generate a square-depth map along with the shadow map.
Utilize multiple channels of a texture map
We may now directly compute the CDF, using the error function (assuming normal distribution):
std::erfdefined in C++, which essentially computes the CDF of a Gaussian distribution using numerical approximations.
We may also apply the following rule:
Chebyshev's Inequality: When
where
Hence we acquire the percentage of texels that has a greater depth.
Performance
Shadow Map Generation:
Squared Depth Map: Parallel, along with shadow map, #pixels
Run time:
Mean of depth in a range:
Mean of depth squared in a range:
Chebyshev:
No samples/loops needed!
Speeding up Blocker Search
Key Idea
Blocker (
Non-blocker (
How to compute? Approximations:
i.e., shadow receiver is a plane.
Performance
With negligible cost.

Issues
Approximation failure leads to significant artifacts.
III. MIPMAP and Summed-Area Variance Shadow Maps
Querying
MIPMAP for Range Query
Allowing fast, approx., square range queries.
However, still approximate even with trilinear interpolation.
Summed-Area Table (SAT) for Range Query
Essentially doing prefix sum.
In
But how to build SAT faster?

[Gamboa et al.]
IV. Moment Shadow Mapping
Motivation
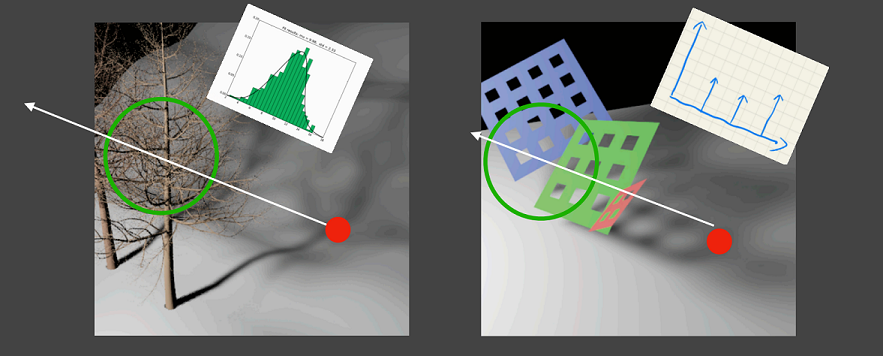
Approximations fail when scene violates the assumption.
Overly dark: May be acceptable
Overly bright: Light leaking/bleeding (industrial term)
Goal of Moment Shadow Mapping:
Represent the distribution more accurately
But still not too costly to store
Use higher order moments to represent a distribution
Moments
Partial Reference: [John A. Rice - Mathematical Statistics and Data Analysis 3ed (Duxbury Advanced) (2006, Duxbury Press)]
Definition: The
VSSM is essentially using the first two orders of moments
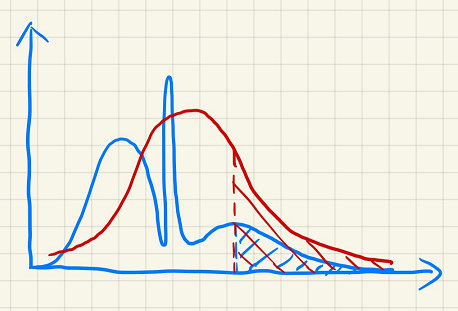
What can moments do?
Approximating a distribution more accurately.
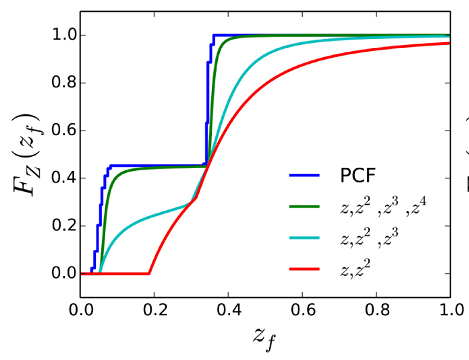
[Peters et al., Moment Shadow Mapping]
Conclusion: first
Usually,
We may restore a CDF given the moment-generating function:
The moment-generating function (MGF) of a random variable
Properties of MGF:
If the moment-generating function exists for
The proof depends on Laplace transform. If two random variables have the same MGF in an open interval containing zero, then they have the same distribution.
Moment Shadow Mapping
Extremely similar to VSSM
When generating the shadow map, record
Packing: Store two 32-bit floating-point into a single one by sacrificing precision.
Restore the CDF during blocker search & PCF.

Pros
Very nice results
Cons
Costly storage (might be fine)
Costly performance (during construction)